Local File Source
To collect log messages from files on the same machine where a Collector is installed, create a Local File Source.
- The Source will run a scan to the target path every two seconds.
- Compressed files that end with the following file extensions are not collected: * tar, bz2, gz, z, zip, jar, war, 7z, rar, exe, dll, xz, or /var/log/(lastlog|btmp|wtmp) binary files
tar.gz files are supported.
If you are editing a Source, metadata changes are reflected going forward. Metadata for previously collected logs will not be retroactively changed.
For details on the limitations of Installed Collectors and how they work see About Installed Collectors.
Supported encoding for local file sources
Local File Sources can collect logs that use the following encoding:
- US-ASCII
- UTF-8 (default)
- UTF-16
- UTF-16BE
- UTF-16LE
- UTF-32
- UTF-32BE
- UTF-32LE
UTF-16 formats are often used internationally; additionally they are common with logs from Microsoft services, such as MS SQL Server and MS SharePoint. When using UTF-16 encoding, the setting applies to all logs collected by that Source. For example, when using a wildcard path expression, ensure that all the files that meet the filter are using the same content encoding.
Avoiding file contention
When the Sumo collector accesses a log file to read its content, the collector opens the file in non-exclusive read mode. The file is opened for read access only, and no read or write locks are requested. File contention issues are still possible, however. For example, if another process attempts to open a file with a read lock at the same time the file is being read by the collector, that attempt will fail. The Add-Content PowerShell cmdlet is known to require a read lock, and should therefore never be used to populate a file being watched by a Sumo collector.
Configure a Local File Source
-
Classic UI. In the main Sumo Logic menu, select Manage Data > Collection > Collection.
New UI. In the Sumo Logic top menu select Configuration, and then under Data Collection select Collection. You can also click the Go To... menu at the top of the screen and select Collection. -
Find the name of the Installed Collector to which you'd like to add a Source. Click Add... then choose Add Source from the pop-up menu.
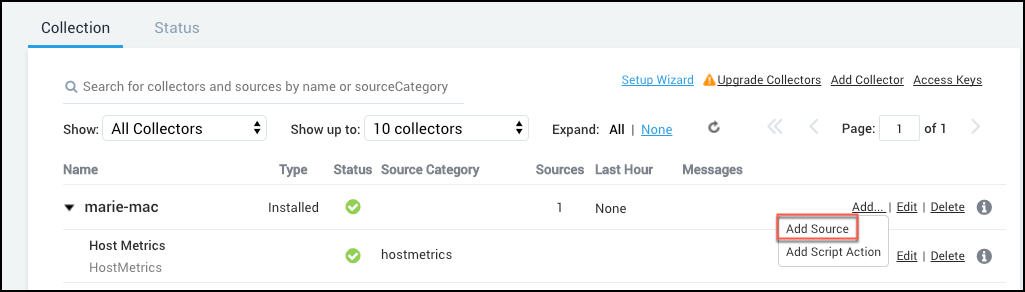
-
Select Local File for the Source type.

-
Set the following choices:
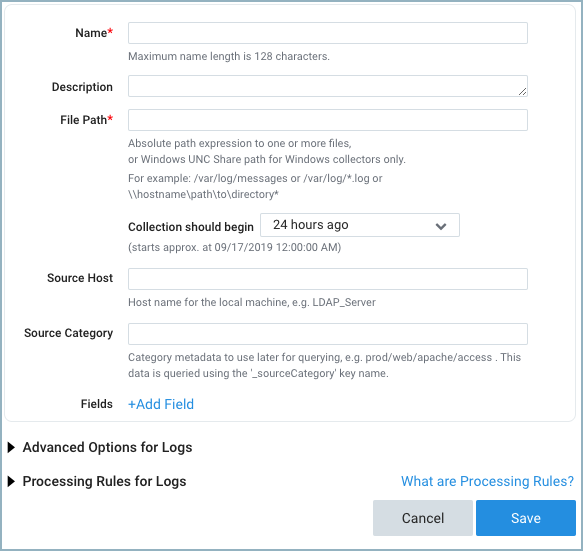
-
Name. Type the name you'd like to display for the new Source. Description is optional.
-
File Path. List the full path to the file you want to collect. For files on Windows systems (not including Windows Events), enter the absolute path including the drive letter. Escape special characters with a backslash (\). If you are collecting from Windows using CIFS/SMB, see Prerequisites for Remote Windows Event Log Collection. Use a single asterisk wildcard [*] for file or folder names [var/foo/*.log]. Use two asterisks [**] to recurse within directories and subdirectories [var/**/*.log]. File paths in both Linux and Windows are case sensitive.
noteYou can have up to 32 nested symbolic links within a path expression.
- Collection should begin. Choose or enter how far back you'd like to begin collecting historical logs. For example, let's say that you have a file with a modified time of
2025-01-16 16:18:18, and the log lines within that file contain message timestamps ranging from2025-01-11to2025-01-16. Now, if Collection should begin is set to2025-01-16, the entire file will be collected including all the messages with timestamps prior to2025-01-16. This is because the Collection should begin is based solely on the file's modified time and not the individual message timestamps within the file.
noteProcessing rules could be used to filter logs as needed. This is done in step 6 of this document.
Review timestamp considerations to understand how Sumo interprets and processes timestamps.
You can either:
- Choose a predefined value from the dropdown list, ranging from "Now" to “72 hours ago” to “All Time”.
- Enter a relative value. To enter a relative value, click the Collection should begin field and press the delete key on your keyboard to clear the field. Then, enter a relative time expression, for example,
-1w. You can define when you want collection to begin in terms of months (M), weeks (w), days (d), hours (h) and minutes (m). When updating the Collection should begin setting, you will need to restart the Collector.
noteIf you set Collection should begin to a collection time that overlaps with data that was previously ingested on a source, it may result in duplicated data to be ingested into Sumo Logic.
- Source Host. The hostname assigned by the operating system is used by default. The Source Host value is tagged to each log and stored in a searchable metadata field called _sourceHost. Avoid using spaces so you do not have to quote them in keyword search expressions. This can be a maximum of 128 characters.
You can define a Source Host value using system environment variables, see Configuring sourceCategory and sourceHost using variables below for details.
- Source Category. The Source Category value is tagged to each log and stored in a searchable metadata field called _sourceCategory. See our Best Practices: Good and Bad Source Categories. Avoid using spaces so you do not have to quote them in keyword search expressions. This can be a maximum of 1,024 characters.
You can define a Source Category value using system environment variables, see Configuring sourceCategory and sourceHost using variables below for details.
-
Fields. Click the +Add Field link to define the fields you want to associate, each field needs a name (key) and value.
 A green circle with a check mark is shown when the field exists in the Fields table schema.
A green circle with a check mark is shown when the field exists in the Fields table schema. An orange triangle with an exclamation point is shown when the field doesn't exist in the Fields table schema. In this case, an option to automatically add the nonexistent fields to the Fields table schema is provided. If a field is sent to Sumo that does not exist in the Fields schema it is ignored, known as dropped.
An orange triangle with an exclamation point is shown when the field doesn't exist in the Fields table schema. In this case, an option to automatically add the nonexistent fields to the Fields table schema is provided. If a field is sent to Sumo that does not exist in the Fields schema it is ignored, known as dropped.
-
-
Set any of the following options under Advanced:
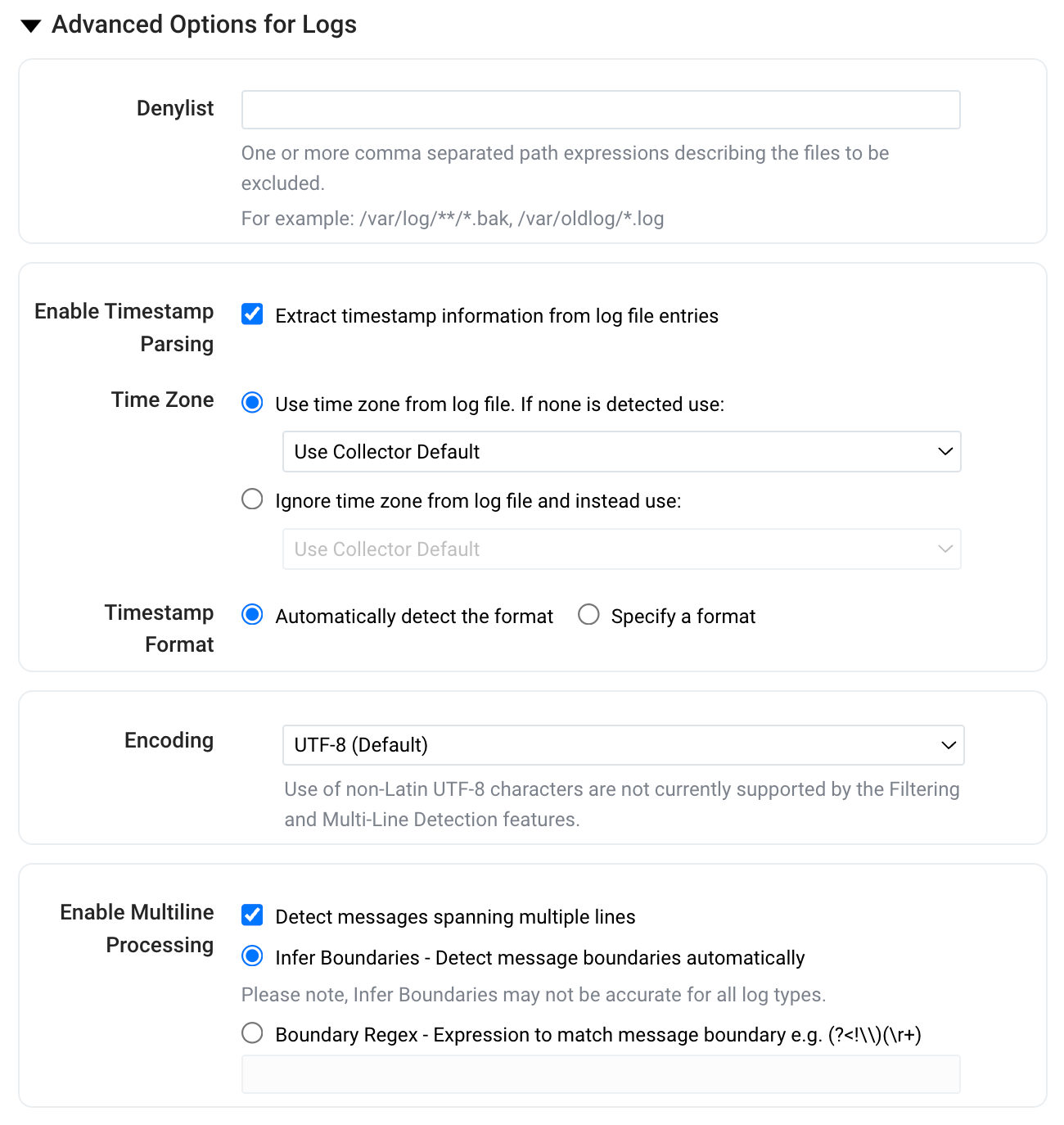
-
Denylist. Enter the path for files to exclude from the Source collection. Wildcard syntax is allowed when specifying unwanted files. For example, if you are collecting
/var/log/*.logbut don’t want to collectunwanted*.log, then specify/var/log/unwanted*.log. You can also exclude subdirectories, for example, if you are collecting/var/log/**/*.logbut do not want to collect anything from/var/log/unwanteddirectory, specify/var/log/unwanted. You do not need to denylist compressed files that end with the file extensions tar, bz2, gz, z, zip, jar, war, 7z, rar, exe, dll, xz, or /var/log/(lastlog|btmp|wtmp) binary files. Sumo Logic, automatically excludes these compressed file extensions when collecting data. tar.gz files are supported -
Enable Timestamp Parsing. This option is selected by default. If it's deselected, no timestamp information is parsed at all.
-
Time Zone. There are two options for Time Zone.
- You can use the time zone present in your log files, and then choose an option in case time zone information is missing from a log message.
- Or, you can have Sumo Logic completely disregard any time zone information present in logs by forcing a time zone. It's very important to have the proper time zone set, no matter which option you choose. If the time zone of logs cannot be determined, Sumo Logic assigns logs UTC; if the rest of your logs are from another time zone your search results will be affected.
-
Timestamp Format. By default, Sumo Logic will automatically detect the timestamp format of your logs. However, you can manually specify a timestamp format for a Source. See [Timestamps, Time Zones, Time Ranges, and Date Formats](/docs/send-data/reference-information/time-reference for more information.
-
Encoding. UTF-8 is the default, but you can choose another encoding format from the menu.
-
Enable Multiline Processing. See Collecting Multiline Logs for details on multiline processing and its options. This is enabled by default. Use this option if you're working with multiline messages (for example, log4J or exception stack traces). Deselect this option if you want to avoid unnecessary processing when collecting single-message-per-line files (for example, Linux system.log). Choose one of the following:
- Infer Boundaries. Enable when you want Sumo Logic to automatically attempt to determine which lines belong to the same message. If you deselect the Infer Boundaries option, you will need to enter a regular expression in the Boundary Regex field to use for detecting the entire first line of multiline messages.
- Boundary Regex. You can specify the boundary between messages using a regular expression. Enter a regular expression that matches the entire first line of every multiline message in your log files.
- Create any processing rules you'd like for the new Source.
- When you are finished configuring the Source, click Save.
You can return to this dialog and edit the settings for the Source at any time.
Configuring sourceCategory and sourceHost using variables
In collector version 19.216-22 and later, when you configure the sourceCategory and sourceHost for a Docker Log Source or a Docker Stats Source, you can specify the value using variables available from Docker and its host.
You build templates for sourceCategory and sourceHost specifying component variables in this form:
{{NAMESPACE.VAR_NAME}}
Where:
NAMESPACEis a namespace that indicates the variable type.VAR_NAMEis the variable name. These are case-sensitive.
The table below defines the types of variables you can use.
Docker engine events log data doesn't support the tagging with metadata.
| Namespace/VAR_TYPE | Description | VAR_NAME |
| container | Container metadata fields provided by Docker for use in the --log-opt tag option. These are automatically added to data points. For more information, see Log tags for logging driver in Docker help. | ID — The first 12 characters of the container ID.FullID — The full container ID.Name — The container name.ImageID — The first 12 characters of the container’s image ID.ImageFullID — The container’s full image ID.ImageName — The name of the image used by the container. |
| label | User-defined labels, supplied with the --label flag when starting a Docker container. This is automatically added to data points. | The name of the variable. Dot characters (.) are not supported. |
| env| User-defined container environment variables that are set with --env|-e flags when starting a container. | The name of the variable. Dot characters (.) are not supported. |
For example:
{{container.ID}}
You can use multiple variables, for example:
{{container.ID}}-{{label.label_name}}-{{env.var_name}}
You can incorporate text in the metadata expression, for example:
ID{{container.ID}}-AnyTextYouWant{{label.label_name}}
The example above uses a hyphen - character to separate variable components. Separator characters are not required. Curly brackets and spaces are not allowed. Underscores and hyphens are recommended.
If a user-defined variable doesn’t exist, that portion of the metadata field will be blank.
How does Sumo Logic handle log file rotation?
Sumo Logic handles log file rotation without any additional configuration. For example, let's say that an active log file is named error.log, and that it's rotated to error.log.timestamp every night. In this case, Sumo Logic detects that the file is rotated, and continues to monitor both the rotated file as well as the new error.log file, assuming that the first 2048 bytes of the error.log file and the rotated file are different.
For the Collector to continue to monitor the rotated log file the path expression needs to match its location. This is important when your log file has data written to it immediately before its rotated. The Collector may not have had enough time to collect the data before the file was rotated. For example, if the log file is named error.log and it's rotated to error.log.timestamp, the path expression should be /path/to/error.log* to match both file paths.
Overlapping paths
Sources with overlapping File Paths will duplicate ingestion. Each Source independently tracks and collects from its specified File Path.
To not have this happen you can use the Local File Source Denylist feature. This allows you to enter a file path to exclude from the Source collection.
Otherwise, instead of denylisting certain paths, you can specify specific log formats to include or exclude on each Source with Processing Rules.
Troubleshooting
Fingerprint
To keep track of what it has already sent to the Sumo service, the Collector tracks a file by its fingerprint (the first 2048 bytes of the file) and by a read pointer that indicates the last line read by the Collector. This fingerprint is then compared to a list of known fingerprints from that Source. If the fingerprint does not match one in the known list we start reading that file's content from the beginning and send it to Sumo. If a matching fingerprint is found in the list we start reading from the last known byte mark of that file. The Collector updates this information approximately every second. A file's fingerprint is retained for some period of time after file deletion, otherwise it is removed.
An issue that could arise is seeing duplicated log messages for a log file that is written to very slowly. When a file is slowly written and the first messages in the file are not larger than 2kb the fingerprint for the Source file can be overwritten with each log line, up to the point those first lines add up to 2kb.
Another possible issue is seeing the Collector not ingesting from a file where the first 2kb of the files match another file previously Collected due to fingerprint matching. In this case, the Collector believes it has already read from the file and could wait at the last known line collected before we see collection begin again at that point.
To resolve these issues you can adjust the fingerprint size to match your needs.
- Stop the current Collector service/process.
- Locate the following Collector configuration file,
/<sumo_install_dir>/config/collector.properties - Add the following parameter to change the default fingerprint size for all Sources on the Collector. The number represents bytes:
collector.wildcard.fpSize=2048 - Restart the Collector process/service.