OpenAI ChatGPT

Version: 1.3
Updated: Jun 26, 2023
The OpenAI API can be applied to virtually any task that involves understanding or generating natural language, code, or images. We offer a spectrum of models with different levels of power suitable for different tasks, as well as the ability to fine-tune your own custom models. These models can be used for everything from content generation to semantic search and classification.
Disclaimer: ChatGPT is an experimental research service provided by a third party, OpenAI, and use of it is subject to their terms and conditions. Output may be inaccurate or unreliable and may contain harmful instructions or biased content. Anything you submit may be used by OpenAI pursuant to their terms and conditions. You are using ChatGPT solely at your own risk. Sumo Logic will not be responsible for your use of ChatGPT.
Actions
- Create Chat Completion (Enrichment) - Using the OpenAI Chat API, with gpt-3.5-turbo and gpt-4 you can do things like:
- Draft an email or other piece of writing
- Write Python code
- Answer questions about a set of documents
- Give your software a natural language interface
- Tutor in a range of subjects
- Translate languages
- Create Text Completion (Enrichment) - The completion endpoint can be used for a wide variety of tasks. It provides a simple but powerful interface to any of our models. You input some text as a prompt, and the model will generate a text completion that attempts to match whatever context or pattern you gave it. For example, if you give the API the prompt, "As Descartes said, I think, therefore", it will return the completion " I am" with high probability.
- List Models (Enrichment) - List and describe the various models available in the API. You can refer to the Models documentation to understand what models are available and the differences between them.
Chat Completion vs Text Completion:
Because gpt-3.5-turbo performs at a similar capability to text-davinci-003 but at 10% the price per token, we recommend gpt-3.5-turbo for most use cases. Both using two different API endpoints.
OpenAI ChatGPT Configuration
Grab your API keys. Log into your OpenAI dashboard and click your profile icon at the top right. Go to View API Keys and click Create new secret key to generate your API secret key.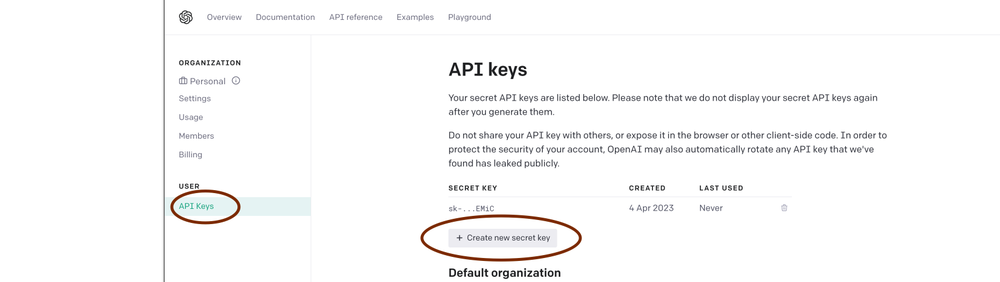
OpenAI ChatGPT in Automation Service and Cloud SOAR
- Access integrations in the Automation Service or Cloud SOAR.
- After the list of the integrations appears, search/look for the integration and click on the row.
- The integration details will appear. Click on the "+" button to add a new Resource.
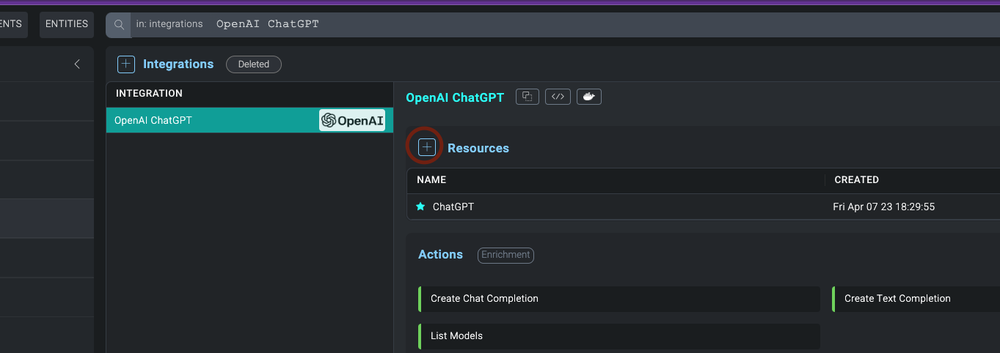
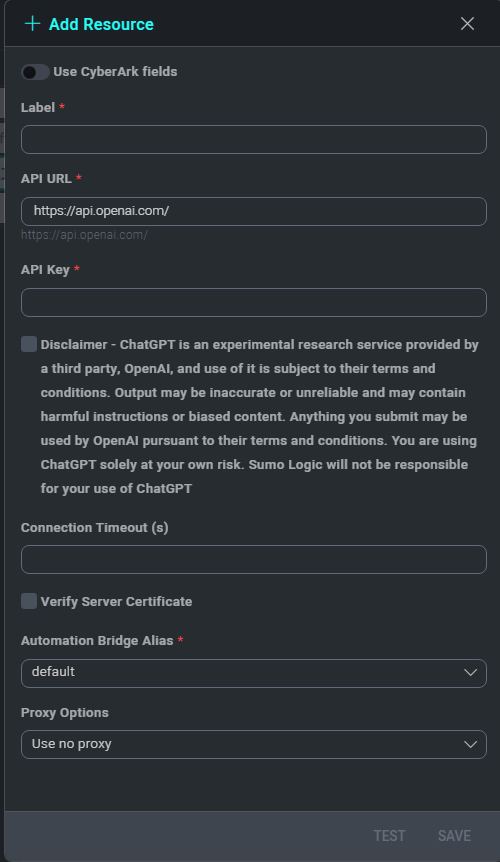
- Populate all the required fields (*) and then click SAVE.
- Label. The name of the resource.
- API URL.
https://api.openai.com/. - API Key. Your OpenAI API Key.
- Disclaimer: Kindly review and acknowledge the disclaimer provided in the integration resource.
- To make sure the resource is working, hover over the resource and then click the pencil icon that appears on the right.
- Click TEST SAVED SETTINGS.

- You should receive a successful notification in the bottom right corner.
Create Chat Completion Action:
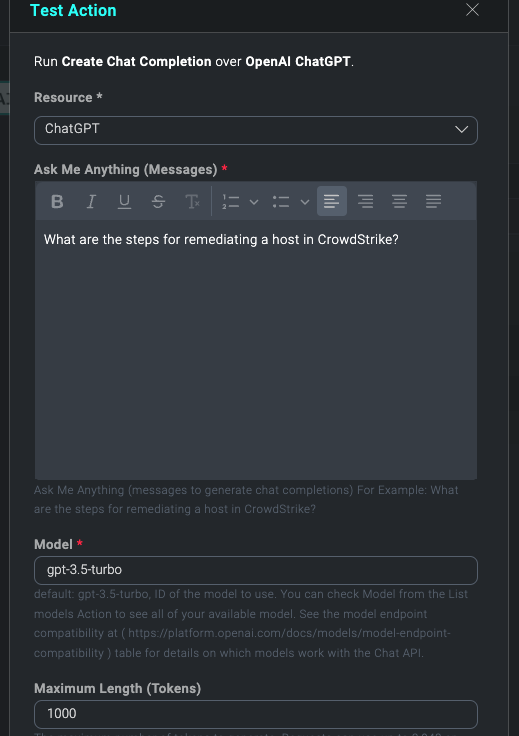
Action Fields:
Ask Me Anything (Messages): Ask Me Anything (messages to generate chat completions) For Example: What are the steps for remediating a host in CrowdStrike?
Model: default: gpt-3.5-turbo, ID of the model to use. You can check the Model from the List models Action to see all of your available models. See the model endpoint compatibility at (https://platform.openai.com/docs/models/model-endpoint-compatibility) table for details on which models work with the Chat API.
Maximum Length (Tokens): The maximum number of tokens to generate. Requests can use up to 2,048 or 4,000 tokens shared between messages and completion. The exact limit varies by model. (One token is roughly 4 characters for normal English text)
Temperature: What sampling temperature to use (Controls Randomness), between 0 and 2. Higher values like "0.8" will make the output more random, while lower values like "0.2" will make it more focused and deterministic. We generally recommend altering this or "Top P" but not both.
Top P: A Number between 0 and 1.0. An alternative to sampling with temperature (Controls Diversity), called nucleus sampling, where the model considers the results of the tokens with "Top P" probability mass. So 0.1 means only the tokens comprising the top 10% probability mass is considered. We generally recommend altering this or "Temperature" but not both.
Frequency Penalty: A Number between 0 and 2.0. How much to penalize new tokens based on their existing frequency in the text so far. Decreases the model's likelihood to repeat the same line verbatim.
Presence Penalty: A Number between 0 and 2.0. How much to penalize new tokens based on whether they appear in the text so far. Increases the model's likelihood to talk about new topics
Change Log
- May 12, 2023 - First upload
- June 26, 2023 (v1.3) - Changed multiline hints to single line